Hippocampus: Context for Fraud

Variance's mission is to build a trustworthy internet. A trustworthy internet is one free from scams, fraud, and abuse. This is a deeply adversarial arms-race, as each rule, heuristic, and ML model provides a new signal for fraudsters to probe for a workaround to find their way in.
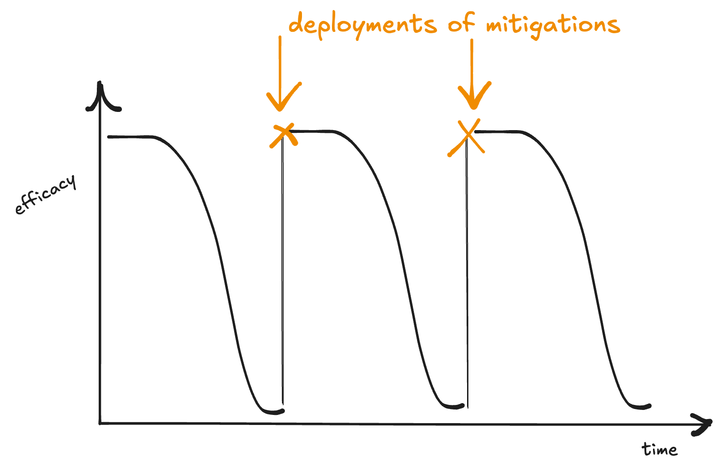
Part of what makes this problem so hard is one of distribution shift. We train and tune traditional classifiers on historical data or fraud samples, but fraud is always changing. We call the rate in which a model decays “adaptation”, and these models must always be constantly retrained and redeployed with fresh data in order to keep up. The gap between these deployments and mitigations opens opportunities for abuse.
When building systems, we often think of infrastructure as robust if it presents self-healing properties, much like Romans did with their concrete. Whereas regular concrete will weather, crack, and crumble after a few decades, Roman concrete withstands thousands of years of wear and tear. The secret unbeknownst to the Romans was the type of volcanic ash they were using: the pumice happened to have the miraculous property to allow for the concrete to heal itself, fill its own cracks, and ultimately outlive the Roman Empire itself.
Where am I going with this? Well, similarly to concrete structures, we argue the central bottleneck of any modern fraud stack is not feature engineering, model power, or even computational resources, but rather one of resilience and malleability. The faster you can get a model to market that captures the latest fraud patterns, the smaller the window of opportunity for exploitation. What if we could build a system that doesn’t need to be bottlenecked on re-training pipelines or model deployments to adapt to changes in behavior?
We view AI agents as a critical part of the self-healing infrastructure of a modern fraud team. Unlike rigid rules and classifiers, AI agents can self-correct and adapt rapidly to changes in behavior. Since AI agent can autonomously query data and build their own plans, they’re not bound by specific features and rules that must be manually managed by data scientists.
Context is all you need
Key to this insight is that if we can supply seconds-fresh context to such a system, then we can build a system that has an edge in adversarial environments. The problem is that most stacks split this into two worlds:
- Real-time features for transactional models and rules.
- Ad-hoc investigations for human analysts poking at data lakes hours or days later.
Fast real-time rules and ML systems can only evolve as quickly as traditional classifiers and human-crafted features can be built out, and investigative workloads are bottlenecked by human ability to build SQL queries on the fly.
Hippocampus, our unified feature store built on top of ClickHouse gives us both in one place. A little bit like the human Hippocampus, which allows us to form and store memories by connecting different experiences and contexts, our Hippocampus acts as a unified context store allowing AI agents to retrieve information with extremely low latency.
The situation
A national grocery delivery app launches a promotion resulting in a sign-up spike. Some are real, but others are bots that are chaining devices, cards, and SIMs. To separate the good from the bad, you need to look at the transactions, but also need the answers to some questions like:
- How many accounts has this /24 IP range created this week?
- Has this SIM been flagged before?
- Which device fingerprints or card bin ranges co-occur with this email domain?
Generating features on Demand
To fully take advantage of the flexibility offered that’s now possible, we wanted to design a data backend that enables the querying of arbitrary features in real-time, while avoiding the cost and limitations of adopting a traditional online and offline feature store. Additionally, we observed AI agents generate and execute queries much faster than human analysts, and truly benefit from low-latency real-time OLAP systems at scale. For our use case, the consistency constraints were acceptable given that we typical do our assessments in streaming environments.
How we built it
We chose ClickHouse for its native support for fast point lookups + window scans, and leaned on incremental materialized views so that we can ingest our data once, and generate two read paths: one for stateful aggregations across time window scans, and another for compact snapshots for point lookups (the latest state per entity/field).
These materialized views are computed on write, and thus can materialize in seconds without requiring additional streaming or batch infrastructure. Since most queries are point lookups, we store events and roll-ups on a per-entity basis (such as users, IPs, devices, etc.), allowing for rapid lookups in ClickHouse. We also leverage ClickHouse’s configurable bloom filter to further filter our data at query time, since many queries take the shape of looking up a particular subset of items matching a specific attribute pair (such as an ip address, or a device identifier).
Below is a simplified version incremental views we use in ClickHouse to support this level of entity aggregation.
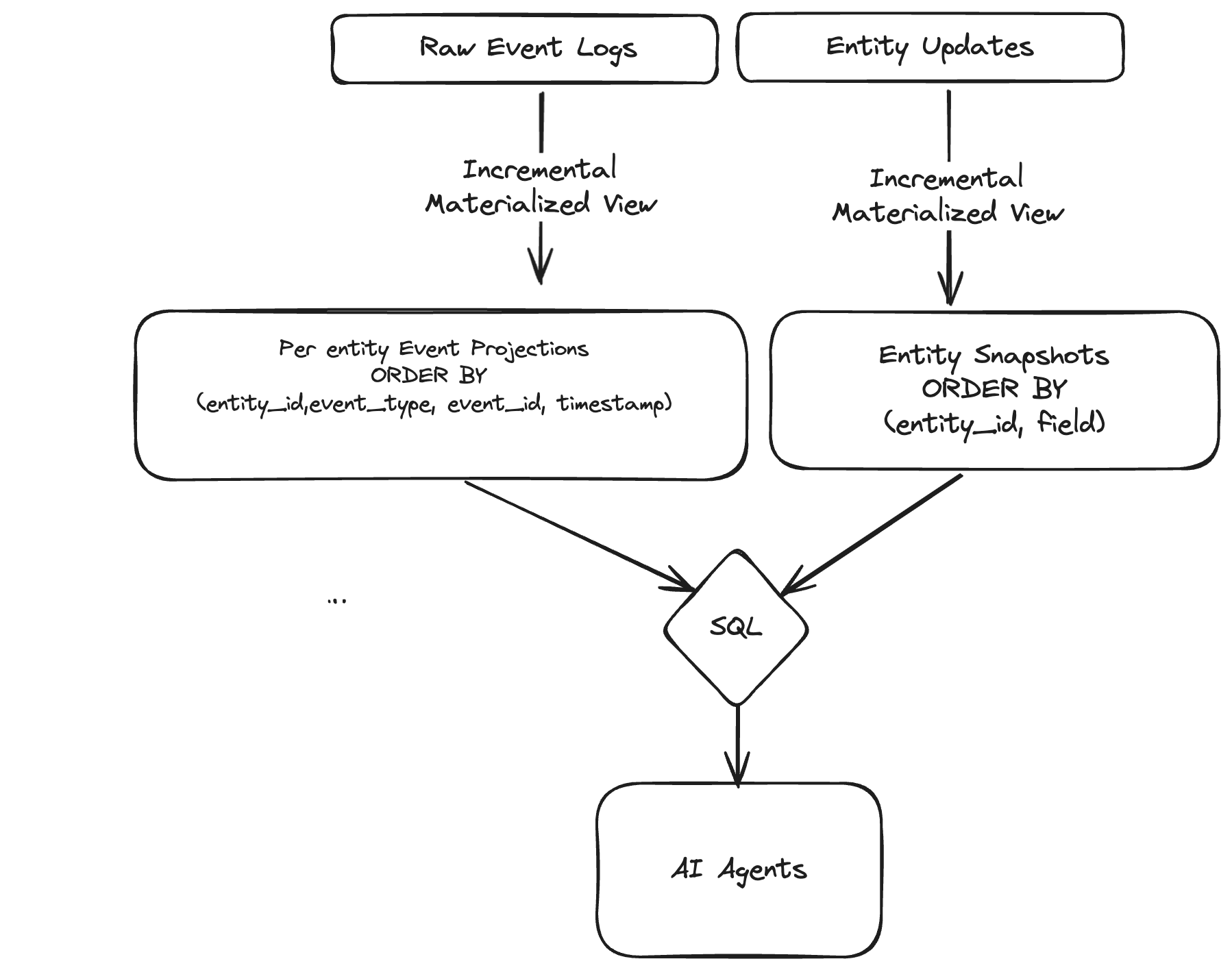
Sample agent query patterns
What makes all of this so simple is that at this point, we can simply just query our data using ordinary SQL. AI agents are already very proficient at building SQL queries, given a few patterns that may be relevant to determining whether something is fraudulent or not.
Point snapshot (current state for an entity)
1SELECT mapFromArrays(
2groupArray(field),
3groupArray(finalizeAggregation(value_state))
4) AS data,
5max(finalizeAggregation(updated_at_state))
6AS data_updated_at
7FROM feature_store.entity_fields_latest
8WHERE entity_id = 'driver_123'
9GROUP BY entity_id;1SELECT
2mapFromArrays(
3groupArray(field),
4groupArray(finalizeAggregation(value_state))
5) AS data,
6max(finalizeAggregation(updated_at_state)) AS data_updated_at
7FROM feature_store.entity_fields_latest
8WHERE entity_id = 'driver_123'
9GROUP BY entity_id;Count a specific pair in a time window
1-- How many times did (device_fp, ip) appear together in the last 7 days?
2
3SELECT countDistinct(event_id) AS cooccurrences
4FROM feature_store.semantic_events
5WHERE occurred_at >= now() - INTERVAL 7 DAY AND event_type IN ('signup','login')
6AND JSONExtractString(data, 'device_fp') = {device_fp}
7AND JSONExtractString(data, 'ip') = {ip};Top co-occuring pair in a window
1SELECT
2 JSONExtractString(data, 'device_fp') AS device_fp,
3 JSONExtractString(data, 'ip') AS ip,
4 countDistinct(event_id) AS c
5FROM feature_store.semantic_events
6WHERE occurred_at >= now() - INTERVAL 24 HOUR
7 AND event_type IN ('signup','login')
8 AND device_fp != '' AND ip != ''
9GROUP BY device_fp, ip
10ORDER BY c DESC
11LIMIT 100;
Benchmarks
To help test this data model, we generated a benchmark of 5 million simulated user logins, devices, and signup events. Note that in production we have seen this model scale to billions of events, across petabytes of data for our largest customers.
With our existing infrastructure, we can query our datasets across three dfiferent use cases: point lookups, as well as some windowed aggregates across entities. These results were conducted on a single ClickHouse instance running with 8GB of memory. We use the clickhouse benchmark tool to run these benchmarks for 50 iterations with a concurrency of 8 per query.
1-- Q1: Point snapshot (current state for one entity)
2SELECT
3 mapFromArrays(groupArray(field), groupArray(finalizeAggregation(value_state))) AS data,
4 max(finalizeAggregation(updated_at_state)) AS data_updated_at
5FROM feature_store.entity_fields_latest
6WHERE entity_id = 'driver_123'
7GROUP BY entity_id;
8-- Q2: Co-occurrence for a specific (device_fp, ip) in last 7 days
9SELECT countDistinct(event_id) AS cooccurrences
10FROM feature_store.semantic_events
11WHERE occurred_at >= now() - INTERVAL 7 DAY
12 AND event_type IN ('signup','login')
13 AND JSONExtractString(data, 'device_fp') = 'd_hot_42'
14 AND JSONExtractString(data, 'ip') = '198.51.100.42';
15-- Q3: Top co-occurring (device_fp, ip) pairs in last 24h
16SELECT
17 JSONExtractString(data, 'device_fp') AS device_fp,
18 JSONExtractString(data, 'ip') AS ip,
19 countDistinct(event_id) AS c
20FROM feature_store.semantic_events
21WHERE occurred_at >= now() - INTERVAL 24 HOUR
22 AND event_type IN ('signup','login')
23 AND device_fp != '' AND ip != ''
24GROUP BY device_fp, ip
25ORDER BY c DESC
26LIMIT 100;
Query Performance Benchmark
As we can see, we are able to achieve sub-sequent latency for these types of queries, and for certain point lookups, we have latencies that are comparable to point lookups to real-time key value stores, despite using an OLAP store for these loads. We think that we're able to optimize the speed of these reads even further overtime by moving frequently queried partitions to hot storage (currnently we only have a single tier of GCS storage configured for all of our storage).
Caveat on Agents and RBAC Security
Letting AI agents write SQL is powerful, but it can threaten stability and security if unscoped.
Beyond prompt constraints, we enforce least privilege at the database boundary using Clickhouse’s RBAC and row-level security. We provision a specific role, that’s coupled to a particular workspace or customer, that only has read-only access.
1CREATE ROLE IF NOT EXISTS namespace_scoped_role;
2GRANT SELECT ON feature_store.semantic_events TO namespace_scoped_role;
3GRANT SELECT ON feature_store.entity_updates TO namespace_scoped_role;
4GRANT SELECT ON feature_store.entity_updates_by_field TO namespace_scoped_role;
5GRANT SELECT ON feature_store.entity_snapshots TO namespace_scoped_role;
6-- 3. Create a Row Policy to enforce isolation on feature_store tables
7CREATE ROW POLICY IF NOT EXISTS tenant_filter ON feature_store.semantic_events, feature_store.entities
8FOR SELECT
9USING namespace_id = getSetting('SQL_namespace_id')
10TO namespace_scoped_case_agent_role;
11-- 4. Create user for agent_1 with the role
12CREATE USER IF NOT EXISTS tenant_scoped_case_agent_for_1
13IDENTIFIED BY '<password>'
14SETTINGS SQL_namespace_id = 1
15DEFAULT ROLE namespace_scoped_role;
Although this is sufficient for our use cases for now, we think we can further harden this security for even more granularity with static validation of the generated SQL so that the agent can only query a certain universe of entities. We can imagine that the primitives built in for gating access may need to look very different for AI agents in the future, to make sure that they do not build malicious queries that may interfere with the workspace.
In our circumstance, as we are using ClickHouse Cloud, we’re able to enforce storage compute isolation to isolate these agentic workloads from the rest of our analytics for our customers.
Wrap-ups
If you’re building anti-abuse defenses and want to talk projections, partitions, and the shape of time, we’d love to compare notes.